
Daten aus Numerischen Wettervorhersagemodellen für Machine Learning nutzen
Bei der Vorhersage wetterabhängiger Prozesse, wie z. B. der Wind- und Solarstromerzeugung, stellen numerische Wettervorhersagemodelle (NWV) die wichtigste zeitvariante Datenquelle dar, da sie die kommenden Tage abdecken, die in vielen Anwendungen von besonderem Interesse sind. Die Auswahl der richtigen Modelle, Parameter und Zeiträume hilft, eine hohe Prognosegüte zu erreichen, wenn für Methoden des Maschinellen Lernens Daten aus numerischen Wettervorhersagemodellen genutzt werden.
Auswahl von NWV-Modellen
Die von den Wetterdiensten zur Verfügung gestellten NWV-Modelle unterscheiden sich stark in der geografischen Abdeckung, der räumlichen und zeitlichen Auflösung und dem Prognosehorizont. Darüber hinaus hat jedes NWV-Modell bestimmte Stärken und Schwächen, die von Bedingungen wie der Region und dem Geländetyp abhängen. Aus diesem Grund ist die Auswahl der NWV-Modelle ein wichtiger Schritt im Prozess der Erstellung eines Vorhersagemodells.
Globale Wettermodelle sind eine solide Basis: Das GFS-Modell der NOAA ist kostenlos verfügbar, während das HRES-Modell des ECMWF Vorhersagen mit hoher Auflösung und Genauigkeit liefert. Diese Modelle, sowie ein Dutzend globaler NWP-Modelle anderer Wetterdienste, decken typischerweise einen Vorhersagehorizont von ein bis zwei Wochen ab. Das macht sie zu einer guten Grundlage für jede Vorhersage.
Regionale Wettermodelle decken viel kleinere Gebiete ab, wie z.B. einen einzelnen Kontinent oder wenige Länder. In vielen Fällen geht eine kleinere geographische Abdeckung mit einer höheren räumlichen Auflösung, aber einem geringeren Vorhersagehorizont einher. Dadurch sind die Modelle schneller zu berechnen, was es den Wetterdiensten ermöglicht, das Modell häufiger zu aktualisieren und die Ergebnisse schneller auszuliefern.
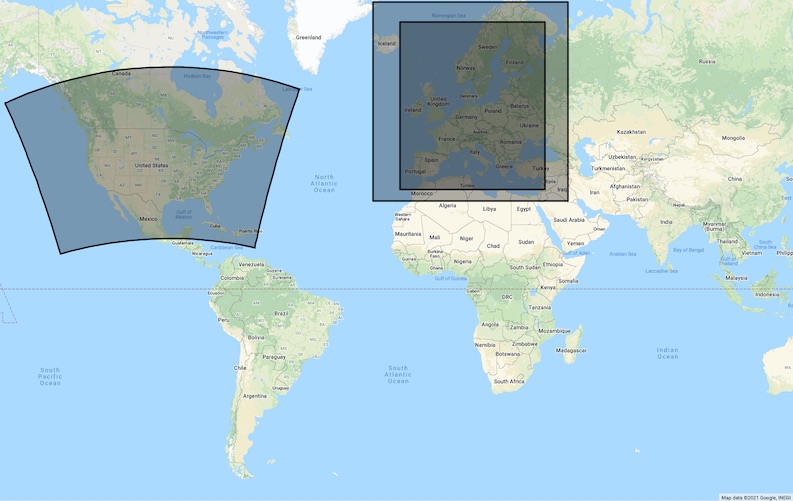
Das North American Mesoscale Forecast System (NAM) von NOAA, EURO4 vom UK Met Office und ICON EU-Nest vom deutschen DWD sind drei Beispiele für regionale NWV-Modelle.
Organisationen können auch ihre eigenen lokalen Wettermodelle betreiben, indem sie ihre eigenen Wetterbeobachtungsdaten in das Modell assimilieren und damit eine Prognose berechnen, die auf die spezifische Anwendung zugeschnitten ist.
Je nach benötigtem Prognosehorizont und dem zu prognostizierenden Standort sind nur bestimmte NWV-Modelle verfügbar. Die höchste Prognosegüte kann jedoch durch eine intelligente Kombination mehrerer NWV-Modelle erreicht werden. Die Kombination der Modelle sollte spezifisch für den Standort und die Referenzdaten sein und die Stärken und Schwächen der einzelnen Modelle berücksichtigen. Dies kann durch einen Machine-Learning-Ansatz erreicht werden.
Nutzung von NWV-Daten für Machine Learning
Beim Entwurf eines Machine-Learning-Modells ist es wichtig, beim Training die gleichen Daten zu verwenden, die auch in der operationellen Vorhersage verwendet werden. In einem ersten Schritt muss der relevante Prognosezeitraum identifiziert werden. Ein typischer Fall ist z.B., dass einmal täglich eine Prognose für den nächsten Tag berechnet wird (Day-Ahead-Prognose). Das bedeutet, dass von einem 4-mal täglich aktualisierten NWV-Modell mit einem Prognosehorizont von mehreren Tagen nur ein einen Tag langer Ausschnitt der Prognosedaten eines der vier Modellläufe verwendet werden kann.
Für die meisten NWV-Modelle stellen die Wetterdienste diese Daten jedoch nicht für historische Zeiträume zur Verfügung, sodass es nicht möglich ist, Modelle mit Daten mit der benötigten Vorlaufzeit zu trainieren. Aus diesem Grund betreibt enercast ein eigenes Archiv mit historischen NWV-Modelldaten in unserem enercast MeteoStore X Repository, das 1 Petabyte an Wetterdaten im Schnellzugriff enthält. Dies ermöglicht es uns, die Prognosemodelle zu trainieren und Backcasts genau mit dem benötigten Prognosezeitraum zu berechnen und die historische Prognosegüte zu bewerten.
Melden Sie sich zu unserem Newsletter an
Hat Ihnen unser Blogbeitrag gefallen und möchten Sie regelmäßige Updates zur Leistungsprognose für erneuerbare Energien erhalten? Dann melden Sie sich jetzt für unseren Newsletter an.


enercast GmbH
Universitätsplatz 12
34127 Kassel
Deutschland
T +49 (5 61) 4 73 96 64-0
F +49 (5 61) 4 73 96 64-99
E info@enercast.de